TurboQuant: How Google Is Redefining AI Efficiency Through Extreme Compression
Artificial intelligence is advancing at an incredible pace—but behind the scenes, one major limitation continues to slow things down: memory. As AI models grow larger and handle longer conversations or more complex tasks, they require massive amounts of memory to function efficiently. This has become one of the biggest bottlenecks in modern AI systems. Now, Google Research is tackling that challenge head-on with a breakthrough called TurboQuant—a new compression technique that could fundamentally change how AI models operate.
ARTIFICIAL INTELLIGENCE
Staff
3/30/20263 min read

The Hidden Problem: AI’s Memory Bottleneck
To understand why TurboQuant matters, it helps to look at how AI models work.
Large language models (LLMs)—like those powering chatbots and generative tools—rely heavily on something called a key-value (KV) cache. Think of it as the model’s short-term memory. It stores previously processed information so the AI doesn’t have to recompute everything from scratch.
This system makes AI faster and more responsive—but it comes at a cost.
The KV cache grows rapidly with longer inputs
It consumes large amounts of high-speed memory
It becomes a major limiting factor in performance and scalability
In fact, memory—not raw compute power—is increasingly the main constraint for modern AI systems.
What Is TurboQuant?
TurboQuant is a new compression algorithm designed to dramatically reduce the memory footprint of AI systems—without sacrificing accuracy.
According to Google Research, it can:
Reduce memory usage by up to 6× or more
Compress data down to extremely low precision (around 3 bits)
Maintain zero loss in model accuracy
That combination is what makes it so significant. Traditionally, compression comes with trade-offs—smaller size usually means lower quality. TurboQuant breaks that pattern.
How It Works (Simplified)
TurboQuant achieves its results through a clever two-step process:
1. Smarter Compression with PolarQuant
First, the system reorganizes data by rotating vectors into a more compressible form. This makes it easier to reduce the amount of information needed while still preserving the overall structure.
This step captures the majority of the data efficiently using fewer bits.
2. Error Correction with QJL
Next, TurboQuant applies a technique called Quantized Johnson-Lindenstrauss (QJL).
This acts like a lightweight error-correction layer:
It uses just 1 extra bit
It removes small inaccuracies introduced during compression
It ensures the AI’s outputs remain precise and unbiased
Together, these two steps allow TurboQuant to compress aggressively while maintaining performance.
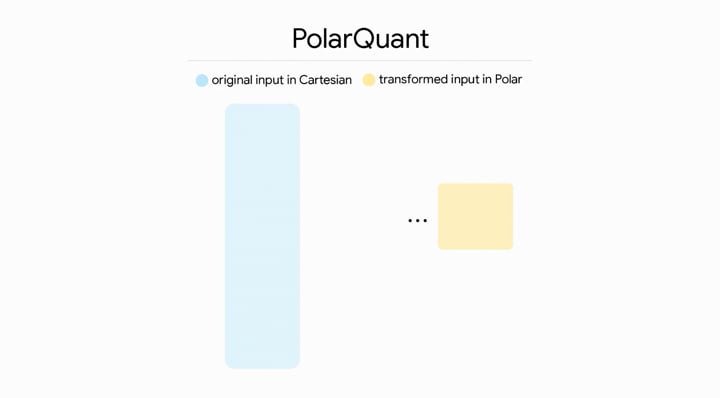
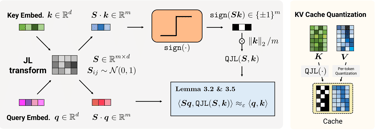
"PolarQuant acts as a high-efficiency compression bridge, converting Cartesian inputs into a compact Polar "shorthand" for storage and processing. The mechanism begins by grouping pairs of coordinates from a d-dimensional vector and mapping them onto a polar coordinate system. Radii are then gathered in pairs for recursive polar transformations — a process that repeats until the data is distilled into a single final radius and a collection of descriptive angles."
Source: Google
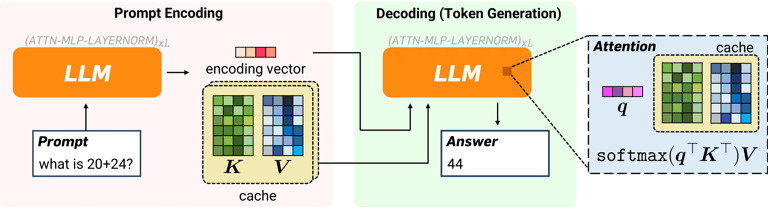
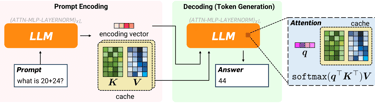
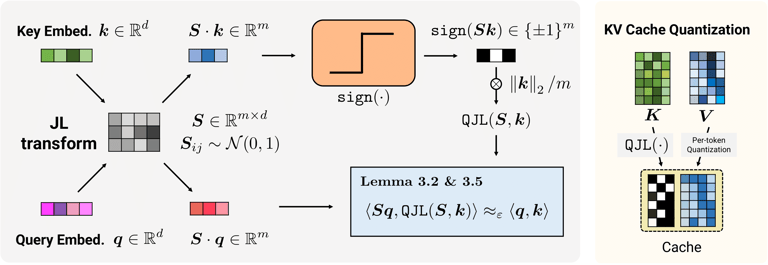
Why This Is a Big Deal
TurboQuant isn’t just a technical improvement—it has wide-reaching implications across the AI industry.
1. Faster AI Systems
By reducing memory load, AI models can process information much more quickly. In some tests, performance improvements reached up to 8× faster processing.
2. Lower Costs
Memory is one of the most expensive parts of running AI at scale. Cutting memory requirements dramatically lowers infrastructure costs for companies deploying AI.
3. Longer Context Windows
With less memory usage per task, models can handle longer conversations and larger datasets without hitting hardware limits.
4. AI on Smaller Devices
TurboQuant could enable advanced AI to run on:
Smartphones
Edge devices
Lower-cost hardware
This opens the door to more accessible and widespread AI adoption.
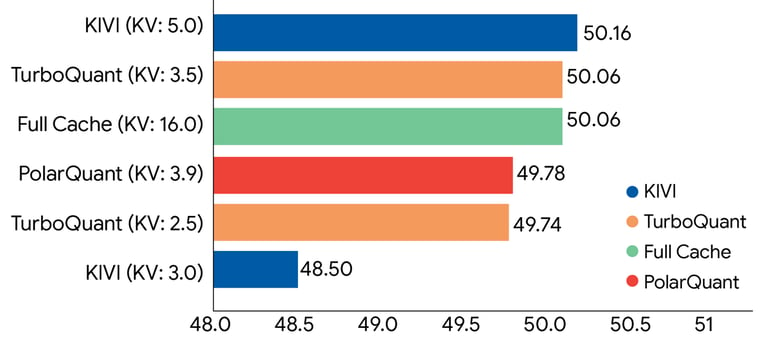
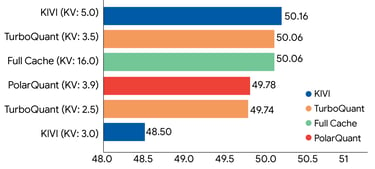
"TurboQuant demonstrates robust KV cache compression performance across the LongBench benchmark relative to various compression methods on the Llama-3.1-8B-Instruct model (bitwidths are indicated in brackets)."
Source: Google
A Shift in How AI Scales
Interestingly, TurboQuant highlights a broader trend in AI development: efficiency is becoming just as important as raw power.
Instead of simply building bigger models, researchers are now finding ways to make existing systems:
Leaner
Faster
More scalable
And while some worry that reducing memory needs could impact hardware demand, others argue the opposite—that increased efficiency will actually drive more AI usage overall.
What Comes Next?
TurboQuant is still emerging from the research phase, with formal presentations expected at major conferences like ICLR 2026.
But its potential is already clear.
If widely adopted, this technology could:
Make AI cheaper and more accessible
Enable new real-time applications
Reduce the environmental footprint of large-scale AI systems
Final Thoughts
TurboQuant represents a major step forward in solving one of AI’s biggest challenges: memory efficiency.
By compressing data more intelligently—without sacrificing accuracy—Google Research is helping unlock faster, more scalable, and more accessible AI.
In a field often driven by “bigger is better,” TurboQuant proves that sometimes, smaller is smarter.
Connect
Engaging storytelling through immersive media solutions.
contactus@lm3official.com
+1234567890
© 2026. All rights reserved.